6.s081 pgtbl lab
Table of Contents
一、xv6 boot
首先要介绍一下xv6中的页表设置,我们从xv6的boot入口开始分析。首先是kernel.ld链接脚本,负责将os的镜像加载到内存中。截取其中的部分代码:
OUTPUT_ARCH( "riscv" )
ENTRY( _entry )
SECTIONS
{
/*
* ensure that entry.S / _entry is at 0x80000000,
* where qemu's -kernel jumps.
*/
. = 0x80000000;
.text : {
*(.text .text.*)
. = ALIGN(0x1000);
_trampoline = .;
*(trampsec)
. = ALIGN(0x1000);
ASSERT(. - _trampoline == 0x1000, "error: trampoline larger than one page");
PROVIDE(etext = .);
}
...
}
这里很自然发现,在编译时,os的kernel镜像的text(也就是代码指令部分)被从0x80000000开始放置。然后入口设置成了_entry。检查entry.S:
# qemu -kernel loads the kernel at 0x80000000
# and causes each CPU to jump there.
# kernel.ld causes the following code to
# be placed at 0x80000000.
.section .text
_entry:
# set up a stack for C.
# stack0 is declared in start.c,
# with a 4096-byte stack per CPU.
# sp = stack0 + (hartid * 4096)
la sp, stack0
li a0, 1024*4
csrr a1, mhartid
addi a1, a1, 1
mul a0, a0, a1
add sp, sp, a0
# jump to start() in start.c
call start
spin:
j spin
由于qemu的设置,代码首先从0x80000000开始执行,也就是这里的_entry的第一条指令。stack0在start中被设置,主要是为每个CPU都设置一个page的stack,关于多核的设置,6.s081不涉及,这里我们也略过。_entry的主要作用就是设置好每个CPU的栈以后,直接调用start函数:
// entry.S jumps here in machine mode on stack0.
void
start()
{
// set M Previous Privilege mode to Supervisor, for mret.
unsigned long x = r_mstatus();
x &= ~MSTATUS_MPP_MASK;
x |= MSTATUS_MPP_S;
w_mstatus(x);
// set M Exception Program Counter to main, for mret.
// requires gcc -mcmodel=medany
w_mepc((uint64)main);
// disable paging for now.
w_satp(0);
// delegate all interrupts and exceptions to supervisor mode.
w_medeleg(0xffff);
w_mideleg(0xffff);
w_sie(r_sie() | SIE_SEIE | SIE_STIE | SIE_SSIE);
// ask for clock interrupts.
timerinit();
// keep each CPU's hartid in its tp register, for cpuid().
int id = r_mhartid();
w_tp(id);
// switch to supervisor mode and jump to main().
asm volatile("mret");
}
在此之前,CPU的特权级都是M(Machine),调用start以后,就应该是S(Supervisor)模式了,在设置了mstatus寄存器之后,写入mepc寄存器为main函数的地址,配置好其他的寄存器,执行mret指令,PC会执行到mepc处的指令,也就是从start调转到main函数:
void
main()
{
if(cpuid() == 0){
consoleinit();
#if defined(LAB_PGTBL) || defined(LAB_LOCK)
statsinit();
#endif
printfinit();
printf("\n");
printf("xv6 kernel is booting\n");
printf("\n");
kinit(); // physical page allocator
kvminit(); // create kernel page table
kvminithart(); // turn on paging
procinit(); // process table
trapinit(); // trap vectors
trapinithart(); // install kernel trap vector
plicinit(); // set up interrupt controller
plicinithart(); // ask PLIC for device interrupts
binit(); // buffer cache
iinit(); // inode cache
fileinit(); // file table
virtio_disk_init(); // emulated hard disk
#ifdef LAB_NET
pci_init();
sockinit();
#endif
userinit(); // first user process
__sync_synchronize();
started = 1;
} else {
while(started == 0)
;
__sync_synchronize();
printf("hart %d starting\n", cpuid());
kvminithart(); // turn on paging
trapinithart(); // install kernel trap vector
plicinithart(); // ask PLIC for device interrupts
}
scheduler();
}
在main函数中会设置好所有的kernel环境,并且创建第一个user process。之后在scheduler函数中,各个进程依据时钟信号抢占CPU执行。本章是虚拟内存相关,我们重点关注kinit、kvminit、kvminithart和procinit函数。总的启动流程:
-> qemu 在启动后会执行 0x8000 0000 处的指令
-> kernel.ld 将 _entry 放到 0x8000 0000 处
-> 执行 _entry,配置 多 CPU 栈
-> 调用 start 函数,写 tp、初始化时钟中断、配置 M 跳转 S 环境(main函数),mret指令
-> mret 使得 CPU 跳转执行 main 函数
-> main 函数初始化内核环境,开启第一个 user process
之后 scheduler 调度所有用户进程的执行
注意: 这些都是在 S 模式下执行的,切换 U 模式是在 scheduler 的 swtch 中,这里放到下个 lab 讲。
二、页表设置(page table)
1. kinit 函数
进入内核环境中,首先第一步就是初始化物理内存kinit:
void
kinit()
{
initlock(&kmem.lock, "kmem");
freerange(end, (void*)PHYSTOP);
}
void
freerange(void *pa_start, void *pa_end)
{
char *p;
p = (char*)PGROUNDUP((uint64)pa_start);
for(; p + PGSIZE <= (char*)pa_end; p += PGSIZE)
kfree(p);
}
void
kfree(void *pa)
{
struct run *r;
if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP)
panic("kfree");
// Fill with junk to catch dangling refs.
memset(pa, 1, PGSIZE);
r = (struct run*)pa;
acquire(&kmem.lock);
r->next = kmem.freelist;
kmem.freelist = r;
release(&kmem.lock);
}
这里初始化 kmem 锁,并且释放了所有从 end 到 PHYSTOP 的内存。PHYSTOP 是 qemu 编译时指定的物理内存主存 RAM 的大小,end 在 kernel.ld 中设置为在data 和 text 结尾的地方,也就是在编译链接完内核代码以后,加载到内存中的结束的位置。可以看到物理内存按照页划分,以链表的格式组织。并且链表的组织形式和 15-213 的 malloc lab 十分相似,都是将每一页物理内存的第一个字节的位置写入下一页内存的地址,整个物理地址空间形式如下图所示:
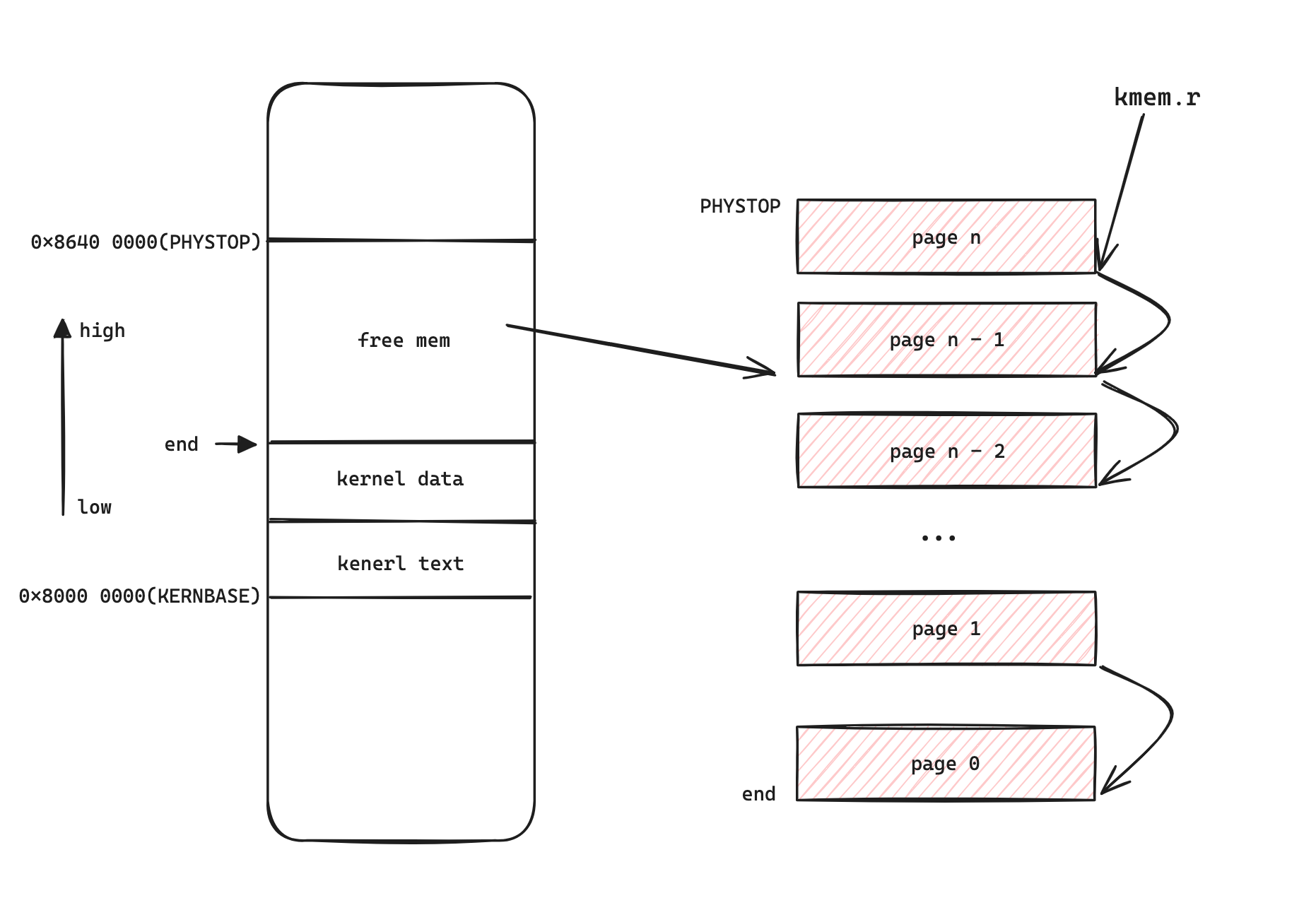
2. kvminit 函数
在初始化物理内存空间之后,为内核创建页表。为了便于内核直接和物理内存交互,所以内核的页表与实际物理内存是直接映射的,不过也有一些例外。
void
kvminit()
{
kernel_pagetable = (pagetable_t) kalloc();
memset(kernel_pagetable, 0, PGSIZE);
// uart registers
kvmmap(UART0, UART0, PGSIZE, PTE_R | PTE_W);
// virtio mmio disk interface
kvmmap(VIRTIO0, VIRTIO0, PGSIZE, PTE_R | PTE_W);
// CLINT
kvmmap(CLINT, CLINT, 0x10000, PTE_R | PTE_W);
// PLIC
kvmmap(PLIC, PLIC, 0x400000, PTE_R | PTE_W);
// map kernel text executable and read-only.
kvmmap(KERNBASE, KERNBASE, (uint64)etext-KERNBASE, PTE_R | PTE_X);
// map kernel data and the physical RAM we'll make use of.
kvmmap((uint64)etext, (uint64)etext, PHYSTOP-(uint64)etext, PTE_R | PTE_W);
// map the trampoline for trap entry/exit to
// the highest virtual address in the kernel.
kvmmap(TRAMPOLINE, (uint64)trampoline, PGSIZE, PTE_R | PTE_X);
}
注意到到目前为止,其实还并没有启用虚拟内存和页表,我们还只是在进行对应的映射,期望为内核实现一个初始的内核页表,逐行分析这里的 kvminit 函数。
- 首先为内核页表分配了一段物理内存,这里的物理内存来自DRAM中的free mem。其实在 kinit 中我们就为内核申请物理内存页配置好了环境。现在我们有了一个空的页表,里面还没有任何内容。
- 接下来的 kvmmap就实现了从 va(虚拟地址)到pa(物理地址)的映射。由于我们期望内核页表的绝大部分都是直接映射到DRAM 的物理内存的,所以这里在预先知道一部分物理内存的地址之后,采用直接映射,这样在之后设置 SATP 之后,就可以顺利根据 VA 找到对应的内存数据。
- 注意这里的例外情况,就是将 trampoline.S 中的 trampoline 汇编代码,虽然本身处在 etext中,但是重新映射到了虚拟地址的顶端,至于为什么这么设计,等到trap的时候再来解释。
这里有一个小小的问题需要思考一下:
我们知道,kalloc 是直接在物理内存中拿到 page 的,但是这里在映射的时候,就不会出现 kvmmap覆盖掉 page处内存的内容吗?
其实根据上面的物理地址空间可以知道,kernel_pagetable 是保存在 free mem中的,而且申请是从大地址到小地址的,而这里的所有直接映射的物理内存,毫无例外都是在 kernbase 这个地址以下的,所以完全不必有这样的顾虑。
这里只创建了一个 页表,但是 xv6是使用了多级页表的,那么我们就要继续看 kvmmap 函数了:
// add a mapping to the kernel page table.
// only used when booting.
// does not flush TLB or enable paging.
void
kvmmap(uint64 va, uint64 pa, uint64 sz, int perm)
{
if(mappages(kernel_pagetable, va, sz, pa, perm) != 0)
panic("kvmmap");
}
// Create PTEs for virtual addresses starting at va that refer to
// physical addresses starting at pa. va and size might not
// be page-aligned. Returns 0 on success, -1 if walk() couldn't
// allocate a needed page-table page.
int
mappages(pagetable_t pagetable, uint64 va, uint64 size, uint64 pa, int perm)
{
uint64 a, last;
pte_t *pte;
a = PGROUNDDOWN(va);
last = PGROUNDDOWN(va + size - 1);
for(;;){
if((pte = walk(pagetable, a, 1)) == 0)
return -1;
if(*pte & PTE_V)
panic("remap");
*pte = PA2PTE(pa) | perm | PTE_V;
if(a == last)
break;
a += PGSIZE;
pa += PGSIZE;
}
return 0;
}
// Return the address of the PTE in page table pagetable
// that corresponds to virtual address va. If alloc!=0,
// create any required page-table pages.
//
// The risc-v Sv39 scheme has three levels of page-table
// pages. A page-table page contains 512 64-bit PTEs.
// A 64-bit virtual address is split into five fields:
// 39..63 -- must be zero.
// 30..38 -- 9 bits of level-2 index.
// 21..29 -- 9 bits of level-1 index.
// 12..20 -- 9 bits of level-0 index.
// 0..11 -- 12 bits of byte offset within the page.
pte_t *
walk(pagetable_t pagetable, uint64 va, int alloc)
{
if(va >= MAXVA)
panic("walk");
for(int level = 2; level > 0; level--) {
pte_t *pte = &pagetable[PX(level, va)];
if(*pte & PTE_V) {
pagetable = (pagetable_t)PTE2PA(*pte);
} else {
if(!alloc || (pagetable = (pde_t*)kalloc()) == 0)
return 0;
memset(pagetable, 0, PGSIZE);
*pte = PA2PTE(pagetable) | PTE_V;
}
}
return &pagetable[PX(0, va)];
}
上面是整个 kvmmap 的调用链,这里设计得实在是很精巧。
mappages 实现了从 pa 到 sz 的一个一个 page 的映射。首先对齐 page,然后依次,一个 page 一个 page 进行 walk。我们要如何实现这个映射呢?要知道我们有三个 page table需要去处理。
- 我们已知的信息有:VA == PA,以及最高一级的 pagetable
- 依据 PA 我们可以知道 level 0 处的 pt 的 PPN
- 依据 VA 我们可以知道每一级 pt 的 PPN 的偏移量
所以我们只需要剩下两级 pt 的 PPN 是多少就可以了,我们目前并没有创建下两级页表,但是我们有最高级 PT,以及 VA,所以我们只需要创建好,并且在最后一级页表的 PPN 协写上 PA 的前 44 位就大功告成了。这里是如何实现的呢?
- 首先根据 VA 和 kernel_pagetable 创建页表,并拿到最后一级的 PTE 指针(walk 函数)
- 往 PTE 指针里面写入 PA 就大功告成
walk 函数中:pagetable[PX(level, va)] 拿到当前级别页表的 PTE内容,如果拿不到(因为 创建页表以后,会把内容置 0),就会申请一块 page,并且写入到这个PTE中,这样就实现了页表的填充。最终返回的是最底层 PTE的地址。
3. kvminithart 和 procinit 函数
kvminithart 是写 satp 寄存器并刷新 TLB作用的,每一次切换页表的必要操作。
procinit 则是为每一个进程都创建了一个内核栈 kstack,并且跟着一个 guard page,防止栈溢出。这里的 kstack 和 trampoline 一样是少数不是直接映射的地址,其中 trampoline 是在 内核的 etext 中,kstack 作为一个指针是在 kernel data 中,但是真正的内存应该还是在 free mem 中,因为来自于 kalloc里面。
到procinit执行完之后,内核页表的地址映射就初始化完毕,其对应的虚拟地址空间也如下所示:
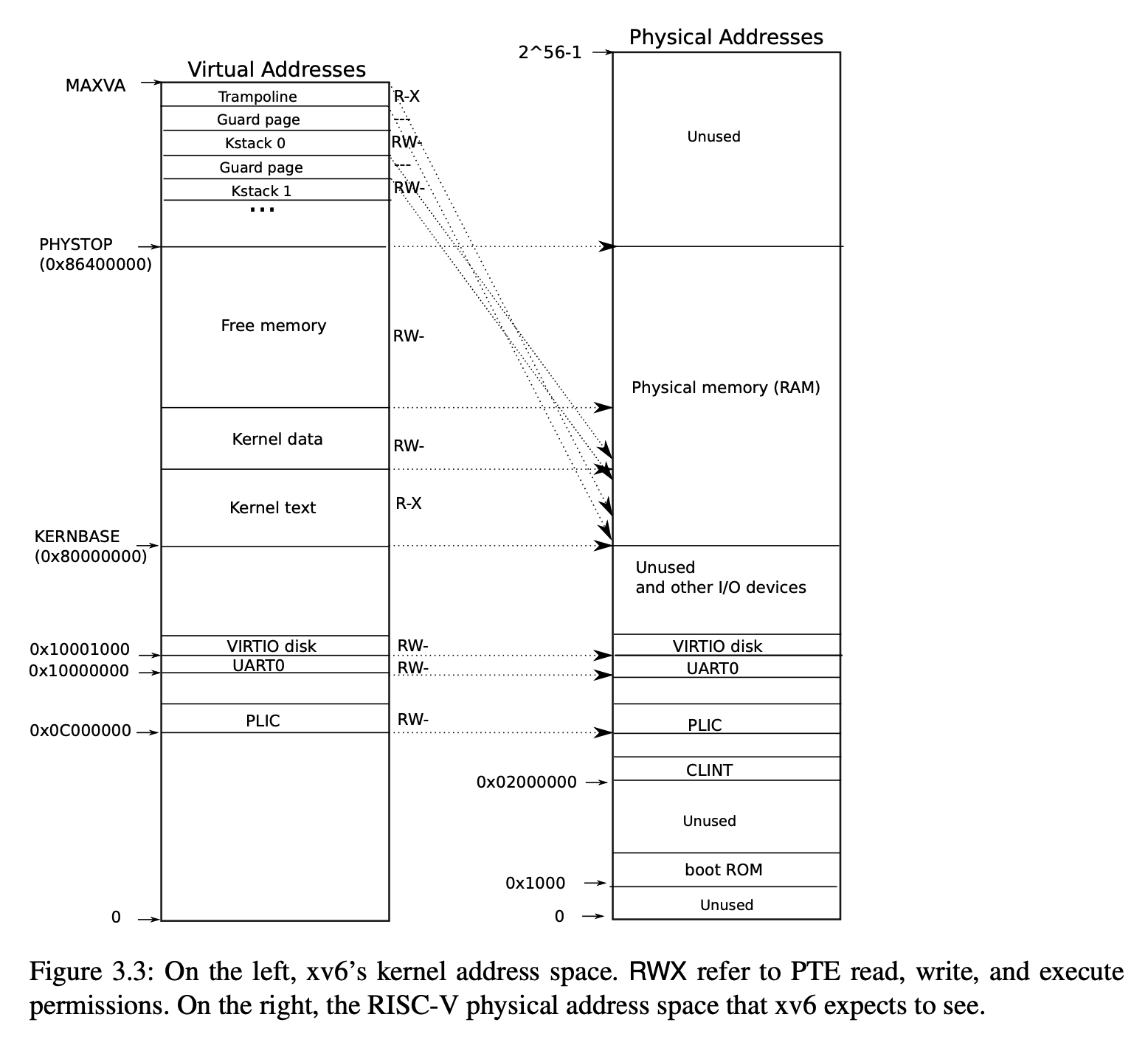
(写完后这里实测了一下,图好像有点问题,128MB 的内存的话,最终的地址应该在 0x8800 0000,这里就不重新画图的)
贴一下打印的地址图(关键部分):
kernel pagetable:在 free mem 的最高处
trampoline 和 p->kstack:在 etext 和 data 中
kstack 的真是物理内存:也在 free mem 高位

三、pgtbl lab
1. Print a page table
void
pteprint(pte_t pte, int level, int num)
{
for(int i = 0; i<=2 - level; i++) {
if(i == 2 - level) printf("..%d: ", num);
else printf(".. ");
}
printf("pte %p pa %p\n", pte, PTE2PA(pte));
}
void
ptprint(pagetable_t pagetable, int level)
{
for(int i = 0; i < 512; i++) {
pte_t pte = pagetable[i];
if(pte & PTE_V) {
pteprint(pte, level, i);
uint64 child = PTE2PA(pte);
if(level != 0)
ptprint((pagetable_t) child, level - 1);
}
}
}
// print the pagetable info to the console
// vm: 27(9 + 9 + 9) + 12
void
vmprint(pagetable_t pagetable)
{
printf("page table %p\n", pagetable);
ptprint(pagetable, 2);
}
第一个实验很简单,不过多讲解。
2. A kernel page table per process
首先为 struct proc 添加 字段:
// Per-process state
struct proc {
struct spinlock lock;
// p->lock must be held when using these:
enum procstate state; // Process state
struct proc *parent; // Parent process
void *chan; // If non-zero, sleeping on chan
int killed; // If non-zero, have been killed
int xstate; // Exit status to be returned to parent's wait
int pid; // Process ID
// these are private to the process, so p->lock need not be held.
uint64 kstack; // Virtual address of kernel stack
uint64 sz; // Size of process memory (bytes)
pagetable_t pagetable; // User page table
pagetable_t kernel_pagetable; // User copy of kernel pagetable
struct trapframe *trapframe; // data page for trampoline.S
struct context context; // swtch() here to run process
struct file *ofile[NOFILE]; // Open files
struct inode *cwd; // Current directory
char name[16]; // Process name (debugging)
};
在 allocproc 中实例化所新加的 kernel_pagetable字段,流程和 xv6 的一样,添加映射和kstack:
// An empty user page table.
p->pagetable = proc_pagetable(p);
p->kernel_pagetable = copy_kernel_pagetable();
copy_kernel_stack(p);
if(p->pagetable == 0 || p->kernel_pagetable == 0){
freeproc(p);
release(&p->lock);
return 0;
}
pagetable_t
copy_kernel_pagetable()
{
pagetable_t kernel_pagetable;
kernel_pagetable = (pagetable_t) kalloc();
memset(kernel_pagetable, 0, PGSIZE);
// uart registers
ukvmmap(kernel_pagetable, UART0, UART0, PGSIZE, PTE_R | PTE_W);
// virtio mmio disk interface
ukvmmap(kernel_pagetable, VIRTIO0, VIRTIO0, PGSIZE, PTE_R | PTE_W);
// CLINT
ukvmmap(kernel_pagetable, CLINT, CLINT, 0x10000, PTE_R | PTE_W);
// PLIC
ukvmmap(kernel_pagetable, PLIC, PLIC, 0x400000, PTE_R | PTE_W);
// map kernel text executable and read-only.
ukvmmap(kernel_pagetable, KERNBASE, KERNBASE, (uint64)etext-KERNBASE, PTE_R | PTE_X);
// map kernel data and the physical RAM we'll make use of.
ukvmmap(kernel_pagetable, (uint64)etext, (uint64)etext, PHYSTOP-(uint64)etext, PTE_R | PTE_W);
// map the trampoline for trap entry/exit to
// the highest virtual address in the kernel.
ukvmmap(kernel_pagetable, TRAMPOLINE, (uint64)trampoline, PGSIZE, PTE_R | PTE_X);
return kernel_pagetable;
}
void
copy_kernel_stack(struct proc *p)
{
uint64 va = p->kstack;
uint64 pa = kvmpa(va);
if(mappages(p->kernel_pagetable, va, PGSIZE, pa, PTE_R | PTE_W) != 0) {
panic("copy_kernel_stack");
}
}
同时 free 的时候,也把 kernel_pagetable free 掉
// free a proc structure and the data hanging from it,
// including user pages.
// p->lock must be held.
static void
freeproc(struct proc *p)
{
if(p->trapframe)
kfree((void*)p->trapframe);
p->trapframe = 0;
if(p->pagetable)
proc_freepagetable(p->pagetable, p->sz);
if(p->kernel_pagetable)
proc_freekernelpagetable(p->kernel_pagetable, 2);
p->pagetable = 0;
p->kernel_pagetable = 0;
p->sz = 0;
p->pid = 0;
p->parent = 0;
p->name[0] = 0;
p->chan = 0;
p->killed = 0;
p->xstate = 0;
p->state = UNUSED;
}
void
proc_freekernelpagetable(pagetable_t pagetable, int level)
{
for(int i = 0; i < 512; i++) {
pte_t pte = pagetable[i];
pagetable[i] = 0;
if(level == 0) continue;
if(pte & PTE_V) {
uint64 child = PTE2PA(pte);
proc_freekernelpagetable((pagetable_t)child, level - 1);
}
}
kfree((void*)pagetable);
}
在 CPU 调度 process 时,切换为进程的内核页表:
for(;;){
// Avoid deadlock by ensuring that devices can interrupt.
intr_on();
int found = 0;
for(p = proc; p < &proc[NPROC]; p++) {
acquire(&p->lock);
if(p->state == RUNNABLE) {
// Switch to chosen process. It is the process's job
// to release its lock and then reacquire it
// before jumping back to us.
p->state = RUNNING;
c->proc = p;
w_satp(MAKE_SATP(p->kernel_pagetable));
sfence_vma();
swtch(&c->context, &p->context);
// Process is done running for now.
// It should have changed its p->state before coming back.
c->proc = 0;
found = 1;
}
release(&p->lock);
}
至此,第二个 lab 结束。
3. Simplify
为了防止系统调用时,内存页表映射的转换,我们需要使得用户的内核页表也包含用户页表本身的内容,所以需要一个将用户页表加载进用户的内核页表的方法:
int
uvmptmap(pagetable_t u_pagetable, pagetable_t k_pagetable, uint64 sz)
{
pte_t *pte;
uint64 pa, i;
uint flags;
if(sz >= PLIC) return -1;
for(i = 0; i < sz; i += PGSIZE) {
if((pte = walk(u_pagetable, i, 0)) != 0) {
pa = PTE2PA(*pte);
flags = PTE_FLAGS(*pte);
flags &= ~PTE_U;
pte_t *p;
if((p = walk(k_pagetable, i, 0)) != 0 && *p & PTE_V) {
uvmunmap(k_pagetable, i, 1, 0);
}
// printf("i: %p, pa: %p, pte: %p\n", i, pa, pte);
ukvmmap(k_pagetable, i, pa, 1, flags);
}
}
// printf("map done\n");
return 0;
}
void
ukvmmap(pagetable_t pagetable, uint64 va, uint64 pa, uint64 sz, int perm)
{
if(mappages(pagetable, va, sz, pa, perm) != 0)
panic("ukvmmap");
}
这里 unmap 的是关于中断的内存,用户用不到,我们直接覆盖掉,直到实验手册所说的 PLIC 的位置。接下来应该思考在什么时候需要调用这里的 u pt 到 k pt 的拷贝。
用户的第一个进程在 userinit 中创建,并且 swtch 机制会使得下次 CPU 调度到该进程时,会从 trapframe 的 pc 开始执行,这里初始化设置成了0,也就是从 initcode 开始执行,所以由于 satp 切换到了进程的内核页表,所以在这之前就必须把同样的内容拷贝进来。
void userinit(void) { struct proc *p; p = allocproc(); initproc = p; // allocate one user page and copy init's instructions // and data into it. uvminit(p->pagetable, initcode, sizeof(initcode)); p->sz = PGSIZE; // prepare for the very first "return" from kernel to user. p->trapframe->epc = 0; // user program counter p->trapframe->sp = PGSIZE; // user stack pointer safestrcpy(p->name, "initcode", sizeof(p->name)); p->cwd = namei("/"); uvmptmap(p->pagetable, p->kernel_pagetable, p->sz); p->state = RUNNABLE; release(&p->lock); }其余的情况就是在创建进程时,除了要 在 allocproc 中创建内核页表,也需要在加载完程序代码和数据到用户页表之后,内核页表也一样需要加载,接下来就是 fork 和 exec,但是这两又不相同的地方:
- fork 进程失败后,是直接不会创建进程,对应的新子进程是要 free 的,所以这里可以正常 free 掉 kernel_pagetable
- 但是 exec 不一样,如果没有成功,进程一样继续执行,这个时候应该不拷贝,返还之前的用户页表,kernel_pagetable 也不应该被 free 掉,不然之后的进程没有办法继续执行了。(这是一个没有思考的地方,卡了我巨久,基本上花了 3、4个小时在 debug)。
sbrk 则需要处理内存不足的情况。具体的改动详见代码。